통계 도와주세요.. 산포 분석할 때
페이지 정보
세분이네분 작성일2017-11-26 23:29관련링크
본문
왜 그런지 이유를 모르겠어서 수식이든 직관적으로든 이유가 있다면 쉽게 알려주시면 감사하겠습니다. 아래와 같은 예를 들어볼께요.
어떤 과자가 낱개 포장(A) 50개 단위로 한 봉지(B)가 만들어지고, 100 봉지(B)를 한 박스(C) 단위로 포장합니다. 즉 한 박스(C) 안에는 낱개 포장(A) 5,000개가 들어 있습니다.
20개 박스를 예로 들면, 박스(C) 20개 = 2,000 봉지(B) = 낱개 포장(A) 100,000개가 됩니다.
- 낱개 포장(A) 100,000개의 중량을 일일이 측정하여 그 100,000개 중량값의 표준편차값을 SIG_All이라 합니다.
- 한 봉지(B) 안에 들어있는 낱개 포장(A) 50개의 중량값의 표준편차값을 봉지마다 각각 구한 후, 그 표준편차값 2,000개의 평균을 SIG_A 라 합니다.
- 한 봉지(B) 안에 들어있는 낱개 포장(A) 50개의 중량값의 평균값을 봉지마다 각각 구한 후, 각 박스(C)마다 그 평균값 100개의 표준편차값 각각 구한 후, 그 표준편차값 20개의 평균을 SIG_B 라 합니다.
- 한 박스(C) 안에 들어있는 낱개 포장(A) 5,000개의 중량값의 평균값을 박스마다 각각 구한 후, 그 평균값 20개의 표준편차값을 SIG_C 라 합니다.
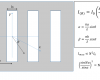
이때 root(SIG_A^2 + SIG_B^2 + SIG_C^2) 가 SIG_All과 완전히 같지는 않지만 거의 유사한 값이 되더라구요.. 이를 근거로 낱개 포장의 중량값의 산포가 한 봉지 내에서/봉지끼리/박스끼리의 산포 중 어느 것의 산포가 크기 때문인지 원인 분석을 합니다.
제가 궁금한 건 SIG_ALL이 예를 들어 SIG_A + SIG_B + SIG_C 이라든가 세제곱근(SIG_A*SIG_B*SIG_C) 이런 식의 값과 유사하지 않고 왜 하필 제곱의 합의 제곱근으로 만족하는지 그 이유 입니다. 뭔가 이론이 있을 것 같기는 한데요..
직관적으로 알려주시면 제일 좋구요.. 수식이 들어있어도 상관없습니다. 알려주시면 감사하겠습니다.
댓글 2
다니님의 댓글
다니
기하평균을 주로 사용하셔서 통계분포를 확인하시는 것 같으십니다.
헌데 문제점은 기하평균의 정확한 정의로 평균을 계산해서 산포를 확인하는 것이 정확한 분포를 알 수 있는 첩경입니다.
일일이 파악하신 SIG_All의 표준편차를 계산하실 때 산술평균을 사용하지는 않으셨는지요?
만약, 그렇게 하셨다면 값이 위의 언급처럼 나오는게 매우 정상적인 현상 입니다.
슈바르츠 부등식을 잘 생각해보시면,
산술평균 >= 기하평균 >= 조화평균 입니다.
세제곱근 기하평균이 아닌 제곱근 기하평균을 쓰셨으니, 산술평균의 값에 근접하게 나오는게 매우 정상적인 현상이다. 라는 의미입니다.
다시 말씀드리지만, 평균의 정확한 정의로 평균값을 쓰시길 권장드립니다.
세분이네분님의 댓글
세분이네분
오래된 글 + 길다란 글에 답변 달아주셔서 감사합니다.
음.. 제가 구하고 있는것은 산포인데.. 산술평균의 값에 근접하게 나온다는 말씀이 무슨 말씀이신지 이해를 못하겠습니다.. SIG_ALL, SIG_C는 표준편차 그 자체이구요.. SIG_A, SIG_B는 표준편차의 산술평균 값이긴 합니다..
SIG_ALL 값을 회사에서 대충 말할 때 root mean square 라고 말들을 하는데, 수식을 따져보면 root sum square 정도 되는 것 같고요..
Hierarchy 구조인 데이터에서 계층별로 낸 산포를 root sum square 한것이 전체 집합의 낱개로 바로 산포를 구한것과 유사하게 나와서 어떤 이론/수식에 의한 것일지 문의드리는 내용입니다.
(혹시나 해서.. 과자 회사는 아닙니다.^^)